


前言
Linux IO是文件存储的基础。本文参考了网上博主的一些文章,主要总结了LinuxIO的基础知识。
linux IO栈
Linux文件IO采用分层的设计。分层有两个好处:
架构清晰; 功能解耦;
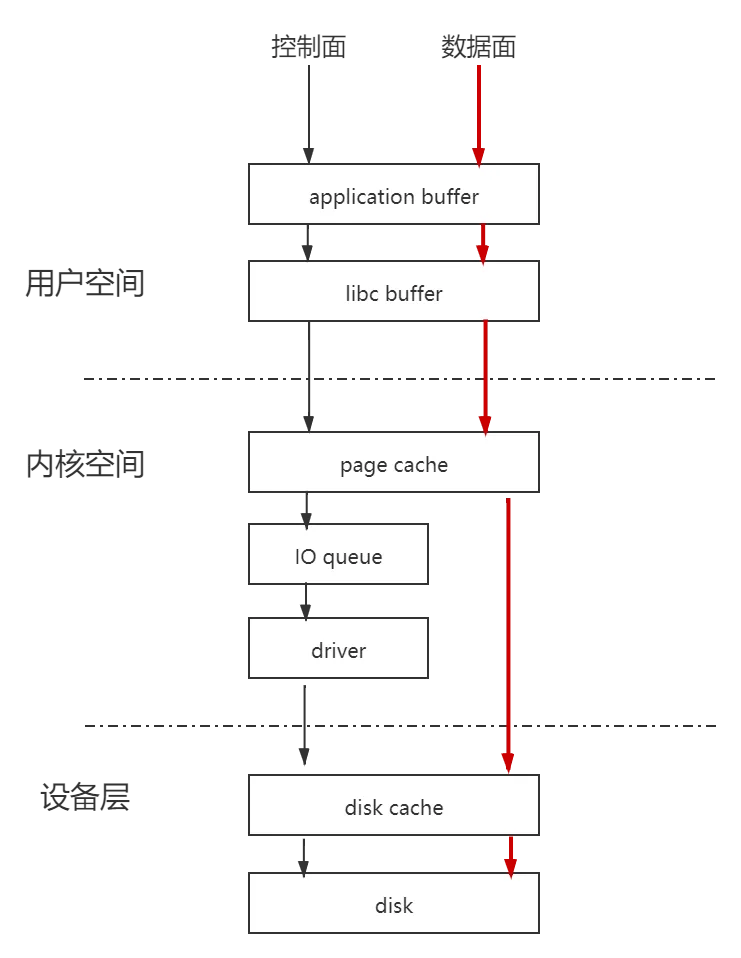
Linux文件IO的时候,从通用性和性能的角度考虑,采用了一个折中的方案来满足我们日常写磁盘。
例如:
void foo() {
char *buf = malloc(MAX_SIZE);
strncpy(buf, src, MAX_SIZE);
fwrite(buf, MAX_SIZE, 1, fp);
fclose(fp);
}上面代码的说明如下:
malloc的buf对应图中的application buffer。调用fwrite之后,操作系统将数据从application buffer拷贝到libc buffer,即c库标准IO buffer。fwrite 返回后,数据还保存在libc buffer,如果这个时候进程退出,这些数据将会丢失,没有写到磁盘上。
当调用fclose的时候,fclose只会刷新libc buffer到page cache,如果确保数据写到磁盘,kernel buffer也必须flush。例如使用sync,fsync。除了fclose方法外,还有一个主动刷新接口fflush函数,但是fflush函数只是将数据从libc buffer拷贝到page cache,并没有刷新到磁盘上,从page cache刷新到磁盘上,可以通过调用fsync完成。
sync会告诉OS,你要将这些数据刷新到磁盘上,但并不能真正保证确实已经写到磁盘上了。属于尽力而为的操作。( According to the standard specification (e.g., POSIX.1-2001), sync() schedules the writes, but may return before the actual writing is done. )sync会将page cache数据送到 disk cache层,至于什么时候写入物理磁盘介质上,则由磁盘控制器自己决定。
从上面可以看到,一个常用的fwrite执行过程,需要经历多次数据拷贝才能最终到达磁盘。
如果我们不想通过fwrite+fflush这种方式,而是想直接写到page cache。这就是我们linux常用的系统调用read/write函数。调用write函数时,实际上是直接通过系统调用将数据从application buffer拷贝到page cache中。但是我们知道,系统调用read/write会触发用户态到内核态的转换这将会一定性能消耗。
如果我们想绕过page cache,直接将数据送到磁盘设备上怎么办?可以通过open的时候携带O_DIRECT属性。这时write该文件,就是直接写到设备上。
如果我们想直接写到磁盘扇区有没有办法?这就是RAW设备写,绕开了文件系统,直接写扇区,例如:fdisk,dd之类的操作就是。
IO调用链
fwrite是系统提供的最上层接口,也是最常用的接口。它在用户进程空间开辟了一个buffer,将多次小数据量相邻写操作先缓存起来,然后合并,最终调用write系统调用一次性写入(或者将大块数据分解多次write调用)。
write函数通过调用系统调用接口,将数据从应用层拷贝到内核,因此write会触发用户态到内核态的切换。当数据到达page cache后,内核并不会立即将数据往下传递,而是返回用户空间。数据什么时候写入磁盘,是由内核IO调度决定,所以write是个异步调用。这一点和read不同,read调用先检查page cache里面是否有数据,如果有,就取回来并返回给用户,如果没有,就同步等待下去并等待有数据再返回给用户。所以read是个同步过程。如果想把write的异步过程改成同步过程,可以将open文件的时候,携带O_SYNC。
数据到了page cache之后,内核有pdflush线程不停的检测脏页,判断是否要写回到磁盘中。然后把需要写回的页提交到IO队列(即:IO调度队列),由IO调用队列的调度策略决定何时写回。
IO调度层
加入IO调度队列的任务并不一定会立即执行,调度层会从全局出发,尽量让整体磁盘IO性能最大化。大致的工作方式是让磁头类似电梯那样工作,先往一个方向走,走到尽头再回来,这样磁盘效率会比较高;磁盘是单向旋转的,不会反复逆时针转动,因为磁头寻道时间比较耗时。
内核中有多种IO调度算法,例如:noop,deadline和cfg,在你机器上,通过dmesg | grep -i scheduler 命令可以查看你的linux支持的算法。当磁盘是SSD时,采用的是随机读写,并没有磁道、磁头,应用于传统机械磁盘的调度算法反而不适用。调度算法中的noop算法,适合配置SSD硬盘。
任务从IO队列出来后,就到了驱动层,驱动层通过DMA,将数据写入磁盘cache。
至于磁盘cache何时写入磁盘介质,这是由磁盘控制器自己决定。如果想确认要写到磁盘介质上,就调用fsync函数。
一致性和安全性
安全性
从上可以看到,数据没有到达磁盘介质之前,可能处于不同的物理内存cache中,那么这个时候如果出现进程退出,内核挂掉,物理机器掉电的情况,数据会丢失吗?
当进程退出后:在application buffer或者libc buffer的数据会丢失。如果数据到了page cache,此时进程退出,即使数据还没有到达硬盘,数据也不会丢失。
当内核挂掉:只要数据还没有到disk cache,都将会丢失。
物理机掉电:此时所有数据都会丢失。
一致性
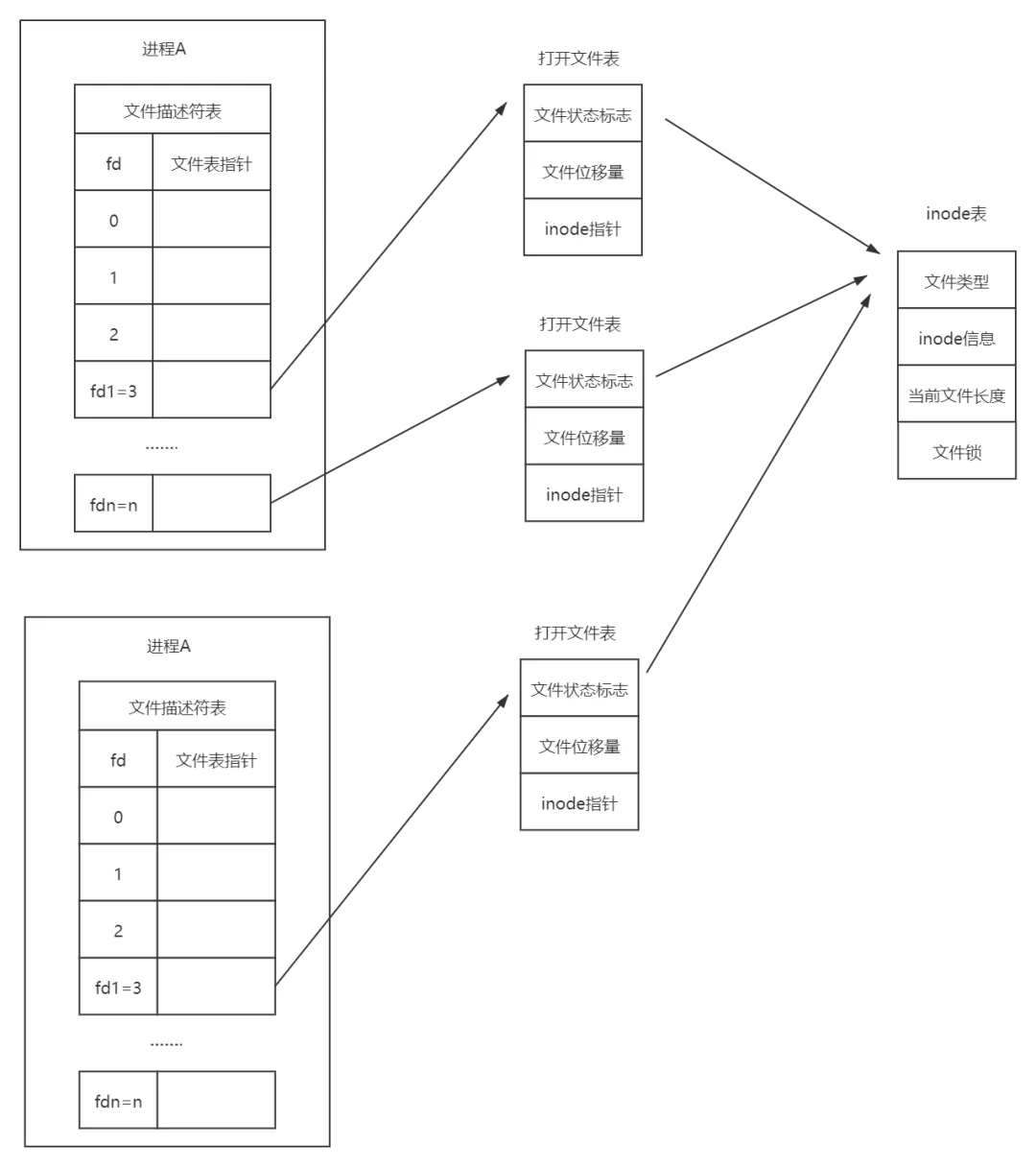
Q:同一个进程A中,多次open同一个文件,然后write数据会怎么样?
fd1 = open("file", O_RDWR|O_TRUNC);
fd2 = open("file", O_RDWR|O_TRUNC);
while (1) {
write(fd1, "hello \n", 6);
write(fd2, "world \n", 6);
}A:先写的数据是会被覆盖的。原因在于同一进程中不同的文件描述符(fd),各自对应一个独立的打开文件表,在打开文件表中有属于自己的文件位移量,开始都是0,然后各自从0开始写,每写一个字节向后移动一个字节,写的位置是重叠的,因此会覆盖。
如何解决被覆盖的问题呢?
必须为每个open指定O_APPEND。文件长度是共享的,当文件被写入数据后,文件长度就会被更新,指定O_APPEND之后,使用不同fd写数据时,都会使用文件长度更新自己的文件位移量,保证每次都是在文件的最末尾写数据,这样就不会出现覆盖。
这里补充一点:同一个进程中多次open同一个文件时,文件描述符是不同的,在同一进程中某个文件描述符被占用,在close之前,是不会被再次分配。
Q:两个进程A和进程B,open同一个文件,然后write数据会怎么样?
A:先写的数据是会被覆盖的。覆盖的原因也是各自有独立的文件位移量。同样指定O_APPEND,使用文件长度更新文件位移量,保证各自操作时,都在文件尾部操作,不会出现相互覆盖的情况。
这里补充一点:不同进程打开同一个文件时,各自使用的fd可能是相等的,之所以相同,是因为不同进程有自己单独的文件描述符池,默认是0~1023,各自分配各自的,是有可能分配到相等的fd
Q:A进程写,B进程读取会写脏吗?
A:会的。读取进程对文件内容变化毫无感知,只是按部就班的读取,直到文件结束EOF。
读文件过程

Linux read文件的流程大致如下:
lib中的read函数首先进入系统调用sys_read;
接着sys_read再进入VFS中的vfs_read、generic_file_read等函数;
接着VFS中的generic_file_read会判断是否缓存命中,如果命中则返回;
如果没有命中,内核在page cache中分配一个新页框,发出缺页中断;
内核向通用块层发起IO请求,块设备屏蔽disk、U盘等差异;
通用块层将bio代表的IO请求发送到IO请求队列中;
IO调度层通过电梯算法来调度队列中的请求;
驱动程序向磁盘控制器发出读取命令控制,DMA方式直接填充到page cache中的新页框;
控制器发出中断通知;
内核将用户需要的数据填充到用户内存中;
然后你的进程被唤醒;
性能问题
磁盘的寻道时间时相当的慢,平均寻道大概在10ms,也就是每秒只能100-200次寻道。
磁盘转速也是影响性能的关键,如果是15000rpm,大概每秒500转。一般情况下,盘片转太快,磁头跟不上,所以需要多转几圈才能完全读出磁道内容。
机械硬盘顺序写 0~30MB左右,顺序读取速率一般 0~50MB左右,性能好的可以达到100多MB;SSD读取达到0~400MB左右。




暂无评论内容