


前言
从本篇起,逆向工厂带大家从程序起源讲起,领略计算机程序逆向技术,了解程序的运行机制,逆向通用技术手段和软件保护技术,更加深入地去探索逆向的魅力。
程序如何诞生?

1951年4月开始在英国牛津郡哈维尔原子能研究基地正式投入使用的英国数字计算机“哈维尔·德卡特伦”,是当时世界上仅有的十几台电脑之一。图中两人手持的“纸带”即是早期的程序,纸带通过是否穿孔记录1或0,而这些正好对应电子器件的开关状态,这便是机器码,是一种早期计算机程序的存储形式。

计算机程序是用来实现某特定目标功能,所以需要将人类思维转换为计算机可识别的语言,从人类语言到电子器件开关的闭合,这中间的媒介便是“编程语言”。
“编程语言”大致分为三类:
1、机器语言,又称机器码、原生码,电脑CPU可直接解读,因该语言与运行平台密切相关,故通用性很差,上面提到的利用卡带记录的便属于该类语言;
2、汇编语言,是一种用于电子计算机、微处理器、微控制器或其他可编程器件的低级语言,亦称为符号语言。在不同的设备中,汇编语言对应着不同的机器语言指令集, 运行时按照设备对应的机器码指令进行转换,所以汇编语言可移植性也较差;

3、高级语言,与前两种语言相比,该类语言高度抽象封装,语法结构更接近人类语言,逻辑也与人类思维逻辑相似,因此具有较高的可读性和编程效率。但是高级语言与汇编语言相比,因编译生成的辅助代码较多,使运行速度相对“较慢”。 java,c,c++,C#,pascal,python,lisp,prolog,FoxPro,易语言等等 均属于高级语言。
学会编程语言各种基本语义语法后,就可以实战了,而实战场所由IDE提供。IDE(集成开发环境Integrated Development Environment)是用于提供程序开发环境的应用程序,目前IDE的种类繁多,不再敖述,只要自己用得顺手、开发效率高、你开心就好。
通过IDE可快速生成程序,根据程序的生成和运行过程,程序大致可分为两类:编译型程序和解释型程序。
编译型程序:程序在执行前编译成机器语言文件,运行时不需要重新翻译,直接供机器运行,该类程序执行效率高,依赖编译器,跨平台性差,如C、C++、Delphi等;
解释型程序:程序在用编程语言编写后,不需要编译,以文本方式存储原始代码,在运行时,通过对应的解释器解释成机器码后再运行,如Basic语言,执行时逐条读取解释每个语句,然后再执行。由此可见解释型语言每执行一句就要翻译一次,效率比较低,但是相比较编译型程序来说,优势在于跨平台性好。
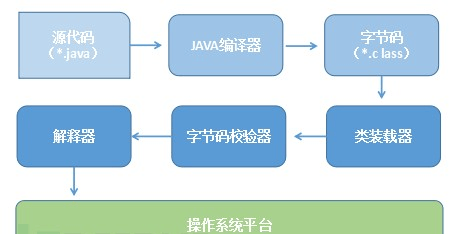
Java首先将源代码通过编译器编译成.class类型文件(字节码),这是java自定义的一种类型,只能由JAVA虚拟机(JVM)识别。程序运行时JVM从.class文件中读一行解释执行一行。另外JAVA为实现跨平台,不同操作系统对应不同的JVM。从这个过程来看JAVA程序前半部分经过了编译,而后半部分又经过解析才能运行,可以说是一种混合型程序,由于该类程序运行依赖虚拟机,一些地方称其为“虚拟机语言”。下图展现各语言之间关系。
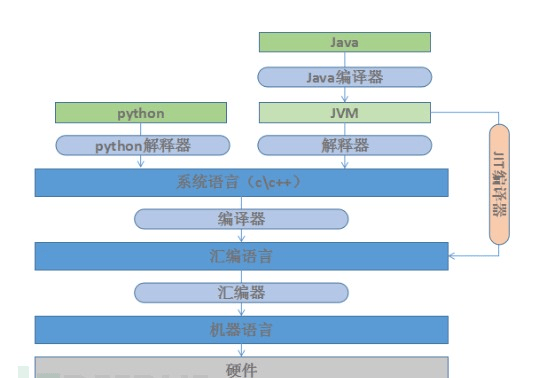
硬件->机器语言->汇编语言->系统语言(C和C++)->解释型语言(python)和虚拟机语言(java),语言的封装程度越来越高,也更加抽象,贴近于人类思维,即“造车前不用再考虑车轮怎么造”。同时,层次越高意味着程序在执行时经历的转化步骤越多,毕竟都要转换为机器语言才能被硬件直接运行,这也是一些高级语言无法应用在效率要求较苛刻场景的原因之一。
Java为了对运行效率进行优化,提出“JIT (Just-In-Time Compiliation)”优化技术,中文为“即时编译”。JVM会分析Java应用程序的函数调用并且达到内部一些阀值后将这些函数编译为本地更高效的机器码,当执行中遇到这类函数,直接执行编译好的机器码,从而避免频繁翻译执行的耗时。
重点看看C\C++语言生成程序的过程及程序是以怎样的形态存储。
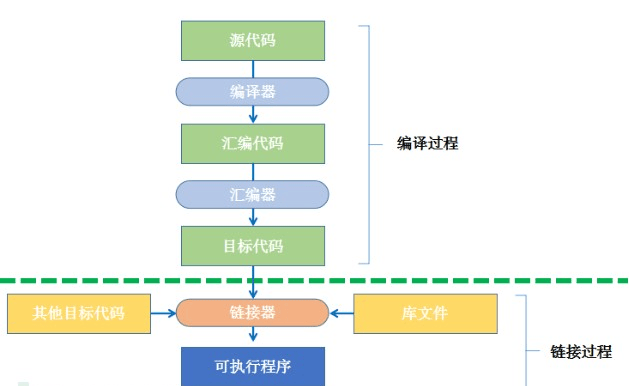
上图为c语言程序的生成过程,主要经过编译、链接两大过程。
编译是指编译器将源代码进行词法和语法的分析,将高级语言指令转换为汇编代码。主要包含3个步骤:
链接是指将有关的目标文件彼此相连接生成可加载、可执行的目标文件,其核心工作是符号表解析和重定位。链接按照工作模式分静态和动态链接两类。
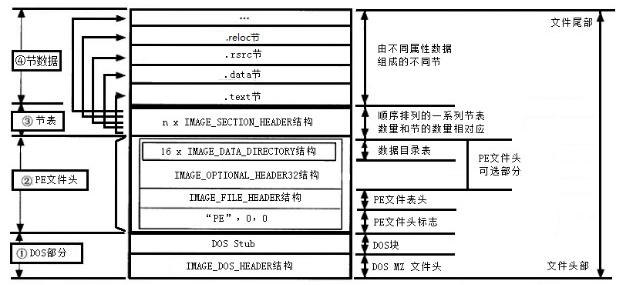
经过编译链接后,程序生成,windows程序则都已PE文件形式存储。
PE文件全称Portable Executable,意为可移植可执行文件,常见的EXE、DLL、OCX、SYS、COM都是PE文件。 PE文件以段的形式存储代码和相关资源数据,其中数据段和代码段是必不可少的两个段。
Windows NT 预定义的段分别为
.text、.bss、.rdata、.data、.rsrc、.edata、.idata、.pdata和.debug。这些段并不是都是必须的,另外也可以根据需要定义更多的段,常见的一些加壳程序则拥有自己命名的段。
在应用程序中最常出现的段有以下6种:
下图为一个标准的PE文件结构。
到此为止,程序就诞生了,如果你对文件形态足够了解,就完全可以向网上的某些大牛一样,纯手工打造一个PE文件。
程序如何运行
程序诞生后,我们就可以运行了,也就是双击程序后的事儿(本节重点描述windows平台程序)。需要说明的是,上面产生的程序文件是存储在硬盘(外存)里的二进制数据,当你双击程序后,windows系统会根据后缀名进行注册表查找相应的启动程序,这里我们编译出的是以exe后缀的可执行程序,则系统对程序进行运行。
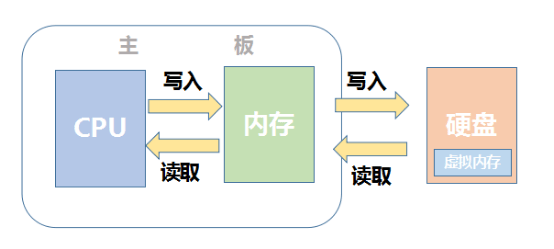
系统并非在硬盘上直接运行程序,而是将其装载进内存里,包括其中的代码段、数据段等。
内存直接由CPU控制,享受与CPU通信的最优带宽,然而硬盘是通过主板上的桥接芯片与CPU相连,所以速度比较慢。再加上传统机械式硬盘靠电机带动盘片转动来读写数据,磁头寻道等机械操作耗费时间,而内存条通过电路来读写数据,显然电机的转速肯定没有电的传输速度快。后来的固态硬盘则大大提升了读写速度,但是由于控制方式依旧不同于内存,读写速度任然慢于内存。
为了程序运行速率,任何程序在运行时,都是有一个叫做“装载器”的程序先将硬盘上的数据复制到内存,然后才让CPU来处理,这个过程就是程序的装载。装载器根据程序的PE头中的各种信息,进行堆栈的申请和代码数据的映射装载,在完成所有的初始化工作后,程序从入口点地址进入,开始执行代码段的第一条指令。
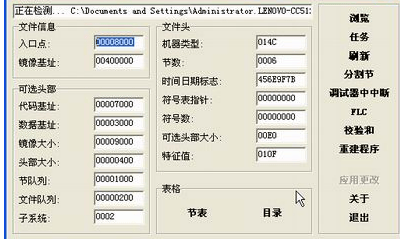
程序从入口点开始顺序执行,CPU直接与内存中的程序打交道,读取内存中的数据进行处理,并将结果保存到内存,除非代码段中还有保存数据到硬盘的代码,否则程序全程都不会在硬盘中存储任何数据。这就好比我们打开文档编辑器去编译文档,不管输入多少内容,在我们点击“保存”前,硬盘上的程序文件都没有变动,输入的数据都只是存储在内存上,如果此时很不幸断电了,内存上的数据会立刻丢失。为了应对这种尴尬局面,一些编辑软件会定期自动保存新数据至硬盘上,以防意外丢失数据的情况发生。
既然程序在运行时需要加载到内存中才能运行,那么问题来了,对于目前体积越来越庞大的游戏来说,岂不是要把40~50G(可见使命召唤系列)的数据全塞进内存里。在某猫上搜索某品牌电脑,按价格排序后,某款3w RMB的移动工作站的内存也只是32G,这显然不满足一下子装载一款游戏的需求。而查看该游戏的运行配置需求,内存需求也只是几个G而已,这是怎么回事呢?
原来,操作系统为解决此问题:当程序运行需要的空间大于内存容量时,会将内存中暂时不用的数据写回硬盘;需要时再从硬盘中读取,并将另外一部分不用的数据写入硬盘。这样,硬盘中部分空间会用于存储内存中暂时不用的数据,这一部分空间就叫做虚拟内存(Virtual Memory)。其中内存交换、内存管理等详细过程,感兴趣的同学可以查阅操作系统相关书籍。
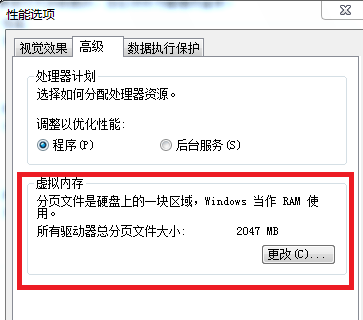
一些同学看到这,就单纯的认为,调整虚拟内存空间即可变向提高内存空间,从而提升运行速度。硬盘的读写速度远远慢于内存,所以虚拟内存和内存频繁进行数据交换会浪费很多时间,严重影响计算机的运行速度。所以同学们还是要努力学习,早日当上高富帅白富美,换高配置电脑吧。
程序如何运行
简要了解计算机程序基础知识后,我们进入【逆向工厂】的正题——逆向。
破解正版软件的授权
由于一些软件采用商业化运营模式,并不开源,同时需要付费使用。为此这些软件采用各种保护技术对使用做了限制,而一些想享受免费的童鞋则对这些保护技术发起进攻,其中的主要技术便是逆向,通过逆向梳理出保护技术的运行机制,从而寻找突破口。
挑战自我、学习提高
crackme是一些公开给别人尝试破解的小程序,制作 crackme 的人可能是程序员,想测试一下自己的软件保护技术,也可能是一位 cracker,想挑战一下其它 cracker 的破解实力,也可能是一些正在学习破解的人,自己编一些小程序给自己破,不管是什么目的,都是通过crackme提高了自身能力。另外, 一些互联网安全公司也会在面试中采取这种形式对应聘者进行测试。
挖掘漏洞与安全性检测
一些安全性要求较高的行业,为确保所用软件的安全,而又无法获取源码时,也需逆向还原软件的运行过程,确保软件的安全可靠。另外,挖洞高手在挖掘漏洞时,经常采用逆向手段,寻找可能存在的溢出点。病毒分析师通过逆向,分析病毒的运行机制,提取特征。
还原非开源项目
当你想模仿某优秀软件实现某功能时,发现该软件并未开源,而又很难从其他渠道获取该软件的具体技术细节,那么逆向也许会帮你敲开思想的大门。
“逆向”顾名思义,就是与将源码变为可执行程序的顺序相反,将编译链接好的程序反过来恢复成“代码级别”。这里之所以用到“代码级别”一词,是因源代码编译是“不可逆”过程,无法从编译后的程序逆推出源代码。
“逆向”通常通过工具软件对程序进行反编译,将二进制程序反编译成汇编代码,甚至可以将一些程序恢复成更为高级的伪代码状态。C\C++程序在经过编译链接后,程序为机器码,直接可供CPU使用,对于这类程序我们使用IDA、OD等逆向程序,只能将其恢复成汇编代码状态,然后通过读汇编代码来解读程序的运行过程机制,显然这对于新手来说,直接阅读汇编代码门槛较高,所以一些逆向工具提供插件可以将一些函数恢复成伪代码级别。
相比C\C++这一类编译运行类程序,依靠java虚拟机、.NET等运行的程序,由于所生成的字节码(供虚拟机解释运行)仍然具有高度抽象性,所以对这类程序的逆向得到的伪代码可读性更强,有时甚至接近与源代码。但是在生成字节码的过程中,变量名、函数名是丢失的,所以逆向出的伪代码中这些名称也是随机命名的,从而给代码的阅读制造的一定障碍。而对于这类易反编译的程序,为了保护软件不被逆向,通常采用代码混淆技术,打乱其中的命名,加入干扰代码来设置各种障碍。
至此,我们把程序恢复成了可读代码,如果你仅仅依靠阅读这些代码来梳理程序运行过程,这叫做“静态调试”。与此对应的“动态调试”则是让程序运行起来,更加直观的观察程序的运行过程。经常编写程序的同学在debug时常常用到“断点”,而在动态调试中,断点起着很大的作用,否则程序将不会暂停下来让你慢慢观察各寄存器状态。
x86系列处理器从8086开始就提供了一条专门用来支持调试的指令,即INT 3。简单地说,这条指令的目的就是使CPU中断(break)到调试器,以供调试者对执行现场进行各种分析。我们可以在想要观察的指令处设置一个断点,则程序会运行到该处后自动停下来;“单步调试”则是每条语句后面都会有INT3指令来阻断程序的运行,而这些INT3是对用户透明的,逆向工具并未将这些指令显示出来。
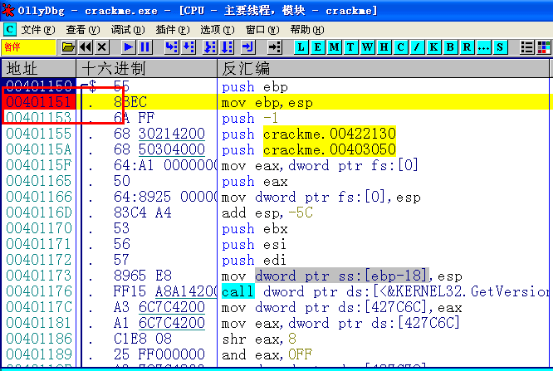
反汇编的多样性
现在大多数程序是利用高级语言如C,C++,Delphi等进行编写 ,然后再经过编译链接,生成可被计算机系统直接执行的文件。不同的操作系统,不同的编程语言,反汇编出的代码大相庭径。反汇编工具如何选择?汇编代码如何分析?如何调试修改代码?这些问题都会让刚入门的新童鞋困惑。
下面我们简单对比c++和c#程序反汇编后得到的代码:
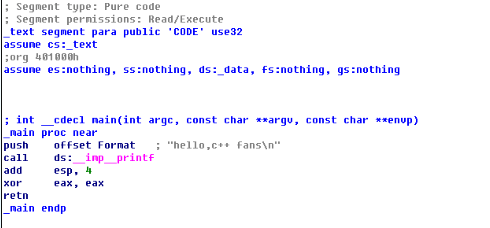
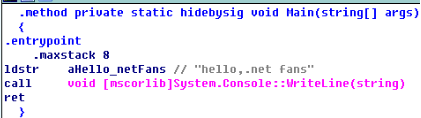
图1是c++程序反汇编结果,图2为.net程序反汇编结果,两者功能都只是打印一句话。C++以push指令将字符串压入栈中,而.net以ldstr指令将字符串压入栈中,调用打印函数结束后,.net反汇编代码直接以ret指令返回结束,而c++反汇编代码先平衡完栈,再执行retn指令返回结束。
由此可见,在反汇编过程中,我们确认好程序的编写语言和运行环境,才可选择适当的工具来反汇编程序。在分析反汇编代码时,如果熟悉高级语言的开发、运行过程及其反汇编指令,那更是事半功倍。
常用的软件分析工具
对于软件逆向分析,分为静态分析和动态分析,常用的软件如下:
静态分析工具
IDA Pro(Interactive Disassembler Professional )
IDA Pro是总部位于比利时列日市(Liège)的Hex-Rayd公司的一款产品。IDA 的主要目标之一,在于呈现尽可能接近源代码的代码,而且通过派生的变量和函数名称来尽其所能地注释生成的反汇编代码,适用于三大主流操作 系统:Microsoft Windows.Mac OS X 和 Linux。IDA Pro提供了许多强大功能,例如函数的交叉引用查看、函数执行流程图及伪代码等,并且也有一定的动态调试功能。同时,IDA pro可以在windows、linux、ios下进行二进制程序的动态调试和动态附加,支持查看程序运行内存空间,设置内存断点和硬件断点。
IDA Pro是许多软件安全专家和黑客所青睐的“神兵利器”。
c32asm
c32asm 是款非常好用的反汇编程序,具有反汇编模式和十六进制编辑模式,能跟踪exe文件的断点,也可直接修改软件内部代码 ,提供输入表、输出表、参考字符、跳转、调用、PE文件分析结果等显示 ,提供汇编语句逐字节分析功能,有助于分析花指令等干扰代码。
Win32Dasm
Win32dasm可以将应用程序静态反编译为WIN 32汇编代码,利用Win32dasm我们可以对程序进行静态分析,帮助快速找到程序的破解突破口。笔者下载的 Win32Dasm还可以附加到正在运行的进程,对进程进行动态调试,但如果原程序经过了加密变换处理或着是被EXE压缩工具压缩过,那么用Win32dasm对程序进行反汇编就没有任何意义了。
VB Decompiler pro
VB Decompiler pro是一个用来反编译VB编写的程序的工具。VB Decompiler反编译成功后,能够修改VB窗体的属性,查看函数过程等 ,VB Decompiler Pro 能反编译Visual Basic 5.0/6.0的p-code形式的EXE, DLL 或 OCX文件。对native code形式的EXE, DLL或OCX文件,VB Decompiler Pro 也能给出反编译线索。

还有对.net程序和delphi程序的静态反汇编分析工具,在以后的章节中会使用到,到时再详细讲解。
动态分析工具
Ollydbg
Ollydbg运行在windows平台上,是 Ring 3级调试器,可以对程序进行动态调试和附加调试,支持对线程的调试同时还支持插件扩展功能, 它会分析函数过程、循环语句、选择语句、表[tables]、常量、代码中的字符串、欺骗性指令、API调用、函数中参数的数目,import表等等 ;支持调试标准动态链接库(Dlls),目前已知 OllyDbg 可以识别 2300 多个 C 和 Windows API 中的常用函数及其使用的参数,是 Ring3级功能最强大的一款动态调试工具。
Windbg
Windbg是Microsoft公司免费调试器调试集合中的GUI的调试器,支持Source和Assembly两种模式的调试。Windbg不仅可以调试应用程序,还可以 对内核进行调试。结合Microsoft的Symbol Server,可以获取系统符号文件,便于应用程序和内核的调试。Windbg支持的平台包括X86、IA64、AMD64。Windbg 安装空间小,具有图形操作界面,但其最强大的地方是有丰富的调试指令。
其它对.net,delphi等程序的动态调试工具在以后的章节中介绍。
辅助工具
从hello world说起
为了让大家直观地了解逆向的过程,我们就从大家最初学习编程时的hello world程序开始讲解:
#include <stdio.h>
void main()
{
printf("hello world!\n");
}这是我们编写的打印hello world程序,是不是看起来很亲切,接下来将编译好的hello
world程序用IDA反汇编,生成的代码如下图:
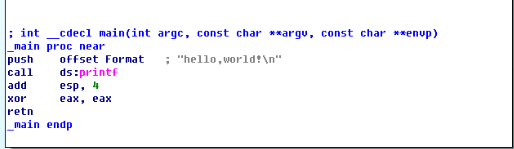
第一行main函数名前面的__cdecl,是C Declaration的缩写(declaration,声明),表示C语言默认的函数调用方法:所有参数从右到左依次入栈,这些参数由调用者清除 。还有__fastcall与__stdcall,三者都是调用约定(Calling convention),它决定以下内容:
push offset Format是将参数压入栈,在这里就是讲要打印的“hello world!\n”压入栈,供printf函数使用,在反汇编程序代码中,如果调用的函数有参数,都是先将函数的参数先用push指令压入栈中,例如:add(int a,int b),调用add函数前,先将参数a和b压入栈,根据 __cdecl调用规则,先push b,再push a,最后再调用add函数。
call ds:printf就是调用printf函数打印“hello world“字符。
add esp, 4是平衡栈,平衡掉刚才压入的函数参数。
xor eax, eax将eax寄存器清零。
retn 返回,程序执行结束。
这就是hello world程序的逆向代码分析,只是举一个简单的例子,真正要逆向分析一个较大较复杂的程序还是有一定难度,需要更多的知识与经验。
Crackme
分析这些程序都能提高个人的程序分析能力,这些程序都有各自侧重的知识点。
下面就以一个验证序列号的crackme小程序作为例子进行破解,得到正确的序列号。
直接运行程序是这样的
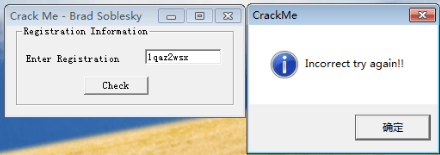
开始破解程序,首先用IDA打开文件
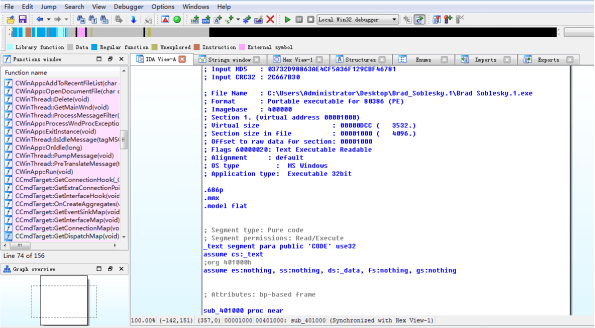
在函数(Function name)窗口中看见CWinApp,CCmdTarget更类,熟悉的同学已经知道该程序使用MFC编写,结合自己的开发经验,就能猜到获取编辑框中的内容用的函数是GetDlgItemText(),定位到调用该函数的位置0×00401557。在之前有三个指令,
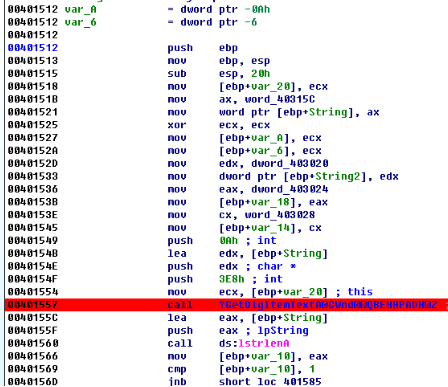
在调用GetDlgItemText()之前有三个push指令,
注意到刚才弹框的提示内容“Incorrect try again!!”,可以在IDA字符串窗口中找到,定位到使用该字符串的位置
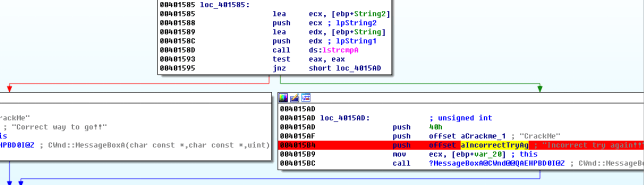
细心的同学已经发现了,在上面loc_401585代码段处有字符串比较(lstrcmpA),比较完成后有两个分支,一个提示输入正确“Correct way to go!!”,另一个提示输入错误 “Incorrect try again!!”,结合上面获取文本输入框内容的代码段信息可以判断,lpString2和lpString1中有一个存储正确的验证码,另一个存储输入的内容,接下来我们用两种方法让我们的验证码通过验证。
获取正确的验证码
在0040158D call ds:lstrcmpA处设置断点,点击Debugger->Start Process或按F9开始动态调试,在程序输入框中随便输入一串字符,实验中输入的是‘1qaz2wsx’,然后点击“Check”控件,程序停在我们设置的断点处,然后查看寄存器ecx和edx中的值,所示如下:
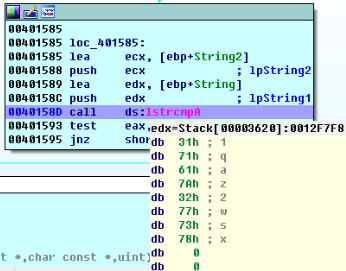
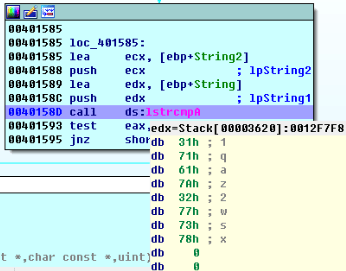
如图所示,ecx寄存器存放的是lpString2:‘’,edx寄存器存放的是lpString1:‘1qaz2wsx’,获得正确验证码”’”’,接下来在程序中试验一下:
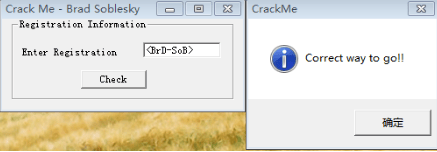
结果正确!
修改二进制代码
修改PE文件,使输入的内容显示正确。在上一小节,程序比较完lpString1和lpString2有两个分支,一个是正确输入的提示框,另一个是错误输入提示框。修改代码跳转,只要跳转到弹出“Correct way to go!!”代码段就可以了,结合代码,当两个字符串不同时会执行jnz short loc_4015AD指令,跳转到loc_4015AD代码段,将jnz指令改为jz,可在两个字符串不同时跳转到“Correct way to go!!”代码段。jnz的十六进制码为75,jz的十六进制码为74,只需将可执行程序中的75改为74就可以。
通过IDA Pro查看十六进制文件窗口找到该跳转指令

用Hedit打开程序,找到该跳转指令

在二进制的文件中该跳转指令在0×00001595处,而不是IDA显示的0×00401595,发生了什么?这涉及到PE文件内存映射方面的基础知识,童鞋们可查阅相关资料。
将跳转指令75修改为74,保存修改后运行,随意输入一段字符串看运行结果:
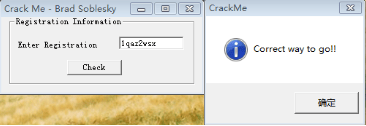
结果正确!




暂无评论内容